I know that similar computational problems use indexing and vector-space representation but how would you build an index of TiBs of almost-random data that makes it faster to find the strictly closest match of an arbitrarily long sequence? I can think of some heuristics, such as bitmapping every occurrence of any 8-pair sequence across each kibibit in the list. A query search would then add the bitmaps of all 8-pair sequences within the query including ones with up to 2 errors, and using the resulting map to find “hotspots” to be checked with brute force. This will decrease the computation and storage access per query but drastically increase the storage size, which is already hard to manage.
As per my other post, this person isn’t doing any of that.
But, since you asked for papers on generic matching algorithms, I found this during the silent conniption fit you sent me into after suggesting that some random tumblr user plugged a tumblr bot directly into a state of the art genomics db.


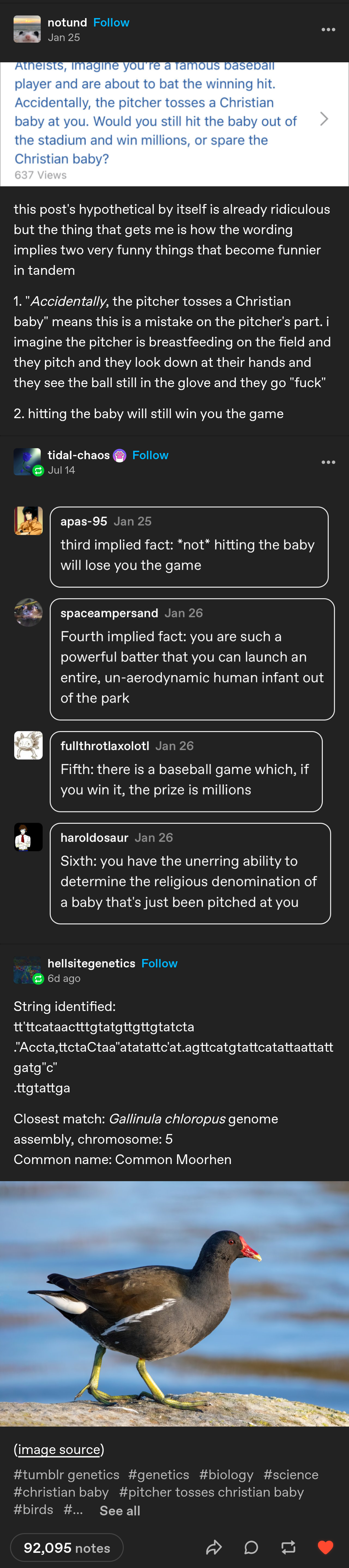{kind=link}
The genomes have likely been indexed to make finding results faster. Google doesn’t search the entire internet when you make a query :P
I know that similar computational problems use indexing and vector-space representation but how would you build an index of TiBs of almost-random data that makes it faster to find the strictly closest match of an arbitrarily long sequence? I can think of some heuristics, such as bitmapping every occurrence of any 8-pair sequence across each kibibit in the list. A query search would then add the bitmaps of all 8-pair sequences within the query including ones with up to 2 errors, and using the resulting map to find “hotspots” to be checked with brute force. This will decrease the computation and storage access per query but drastically increase the storage size, which is already hard to manage.
As per my other post, this person isn’t doing any of that.
But, since you asked for papers on generic matching algorithms, I found this during the silent conniption fit you sent me into after suggesting that some random tumblr user plugged a tumblr bot directly into a state of the art genomics db.
https://link.springer.com/article/10.1007/s11227-022-04673-3
Please note that while, yes, they ran this test on a standard office computer, they were only searching against 12 million characters.
A single terabyte of characters would be more like 1 trillion characters. A pebibyte would be more like 1 quintillion.
… much, much, much longer processing times.