

- cross-posted to:
- [email protected]
You must log in or register to comment.
Back during prohibition in the US, there was a product called Vine-Glo that was a brick of grape concentrate. It came with a warning: “After dissolving the brick in a gallon of water, do not place the liquid in a jug away in the cupboard for twenty days, because then it would turn into wine.”
Definitely don’t use uBlock Origin’s zapper mode to get rid of elements on the page that are blocking your view.
I’ve used ublock for years and only recently discovered the zapper and it’s my new favorite thing on the internet
I often forget YouTube shorts are a thing because i zapped them away.
You sir are a gentleman and a scholar, cheers for this
I don’t generally use it, but safari got this baked in recently
Disabling JavaScript through ublock origin also does the same (horrible) thing, frequently.
I have been using inspect element to manually remove ads and other annoying things
Thanks for reminding me!
^ This person adblocks
cocks the element zapper Say hello to my little friend!
On mobile Firefox, two right swipes in the middle of the screen closes zapper mode. It is not clear or obvious, but it works.
Then you just get an unblocked half an article
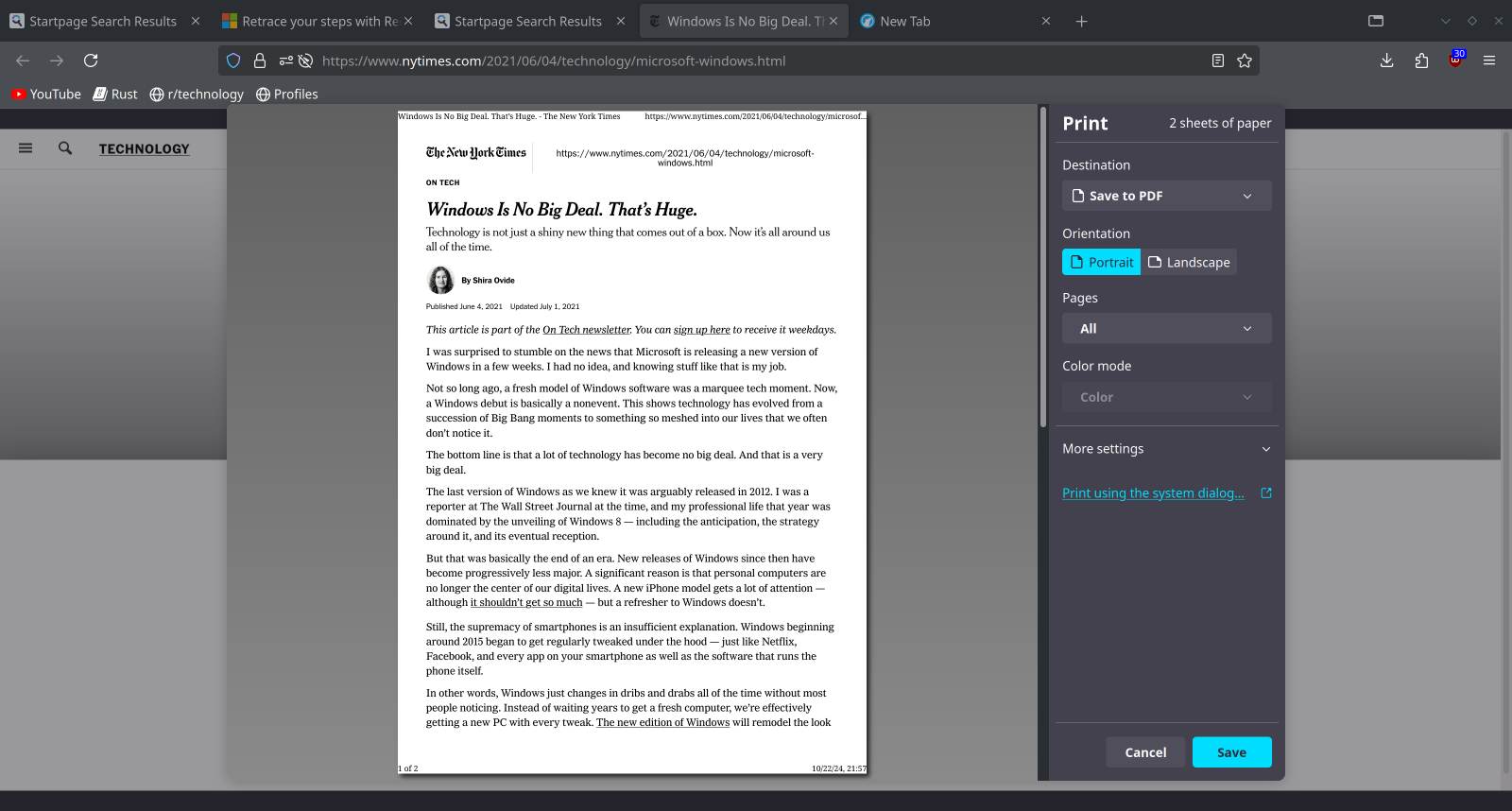
Huh. I just Ctrl+P before the paywall comes up. Then I can print to a PDF and view it the way it was meant to be.
That’s exactly what the 3rd post said.
“Append…before”, AKA “prepend”!
And never, EVER disable JavaScript on that website and reload the page! Not even if your Ad blocker lets you selectively do it.
Wow, I feel like the most upvoted solutions here don’t work, and meanwhile some obvious and widely known alternatives are being completely overlooked.
❌ Inspect Element - many modern sites don’t even include the full article in the paywalled html, so this wouldn’t work. Also sitting there and mousing over elements and deleting them one by one, is tedious, it’s easy to accidentally delete an element that encloses the content you intended to keep, or to drive yourself crazy trying to figure out how elements are nested.
❌ Ublock Zapper - a similar to the above, won’t work on stub articles, and just janky because you’re manually zapping things
❌ Disabled JavaScript - Similar to the above, same problem because many articles are stubs anyway. And the HTML layers that block your view don’t have to be done with JavaScript.
❌ Rapid copy and paste of the article to notepad or rapidly printing the screen - similar problem to the above, lots of places just post the stub of an article, and besides nobody should live their life this way rapidly trying to print screen or copy everything. If you’re trying to do a quick copy you’re going to grab all kinds of gobbledygunk from the page and probably have to manually filter it out.
❌ Reader Mode - Your browsers reader mode will be hit and miss because, again, many sites post stub articles, and it’s possible the pay wall stuff will just get formatted into the reader mode song with an incomplete article.
✅ Archive.is - works!
✅ Pocket and Instapaper - amazingly, nobody has mentioned these even though they’re probably the longest running (dating back to 2007-2008), possibly most widely known, and most consistent solutions that still work to this day. They keep their own local caches of articles, so it’s not depending on the full content being visible on the page.
✅ Other dedicated extensions - Dedicated browser extensions seem to work, but be careful what you’re signing yourself up for.
🤷♀️ Brave - It works, but, it’s a Chromium supported browser, so ultimately Google controls the destiny and can drive Chromium to incorporate fundamental frameworks supporting DRM and pushing their preferred web standards.
For poorly paywalled sites, just hit F9. Displays screen reader text. Accessibility, y’all.
Thank you so much! I already did it! (Smash Ctrl+P as fast as possible)
feds coming fo yo ass now you better run
If a website sends all the data of an article to you, it’s yours. They can’t take it away. There’s no basis to make the argument anything is owed to the website at that point.
Will someone PLEASE think of the shareholders?!
Thank you for the great advice. We should share this to a maximum of people. We don’t want people to get in trouble for violating copyright especially when done accidentally.
do not right click inspect element on the paywall window and then delete the code & re-enable scrolling (i always forget how to, but don’t google it)
the downside is that sometimes half the article is neutered anyway
Independent journalism is dead because journalists need to be paid. And you guys celebrate this? Yeah, sure, keep reading your “free” news. Just remember to ask yourself who do you think is paying for it and why.
Who? The biggest corporate entity without soul that is consuming our humanity and enacting a war on other corporations that continually escalate the destruction of our planet and the enshittening of all our work ultimately ending in total destruction of our happiness first and then our resources then our actual lives as the entity wins and is left alone controlling earth which was it’s objective then it falls apart with not even a satisfactiory ding to mark its completion because nobody is left it it all over. I think it’s that entity. Was I right?
Ad companies with biases and normies/boomers who pay for it without any second guess.
In case anyone wanted to know.
LOL the first trick is my go to. I regularly read Washington Post articles in notepad.
Many sites don’t work like that and don’t even load the content from the server before the paywall check.
But I have a trick that work 100% of the time. Just don’t read those sites.
I get that journalism and entertainment magazines have workers and need to be paid BUT:
They were getting paid when I could pay a cheap physical newspaper if I want to read it and usually had those for free anyway. As you’ll get newspapers on most public places and one single newspaper would serve a whole family. In my house we didn’t really paid more than 4€ a month and got physical things that you could just keep. Now with digital distribution you own nothing and it is far more expensive. So… No. Also they get a ton of public money through institutional advertisement, so I’m already basically paying for them without getting access to their content.
So unless they are willing to change their model I’ll just refuse to live. I’m happier without their clickbaits anyway.
So unless they are willing to change their model I’ll just refuse to live.
Wait what
Saddest typo ever.
I just won’t tell this to my psychologist, just in case.
It’s safe with us












{kind=link}