

Sadly, that’s not code Linus wrote. Nor one he merged. (It’s from git, copied from rsync, committed by Junio)
here you go, linux 0.01


Isn’t that from 1991 while the quote is from 1995? If we’re nitpicking maybe we shouldn’t time travel 🤓
Damn it Time Patrol! You can’t stop me!
- Time Troll
I mean it was 0.01, at that point he was screwed anyway, and he fixed his program.
He wouldn’t make that statement unless he experienced the horror himself.
Now, if he still does it these days…
I’ve heard similar from the worst first year CS students you could ever meet. People talk out their ass without the experience to back up their observations constantly. The indentation thing is a reasonable heuristic that states you are adding too much complexity at specific points in your code that suggests you should isolate core pieces of logic into discrete functions. And while that’s broadly reasonable, this often has the downside of you producing code that has a lot of very small, very specific functions that are only ever invoked by other very small, very specific functions. It doesn’t make your code easier to read or understand and it arguably leads to scenarios in which your code becomes very disorganized and needlessly opaque purely because you didn’t want additional indentation in order to meet some kind of arbitrary formatting guideline you set for yourself. This is something that happens in any language but some languages are more susceptible to it than others. PEP8’s line length limit is treated like biblical edict by your more insufferable python developers.
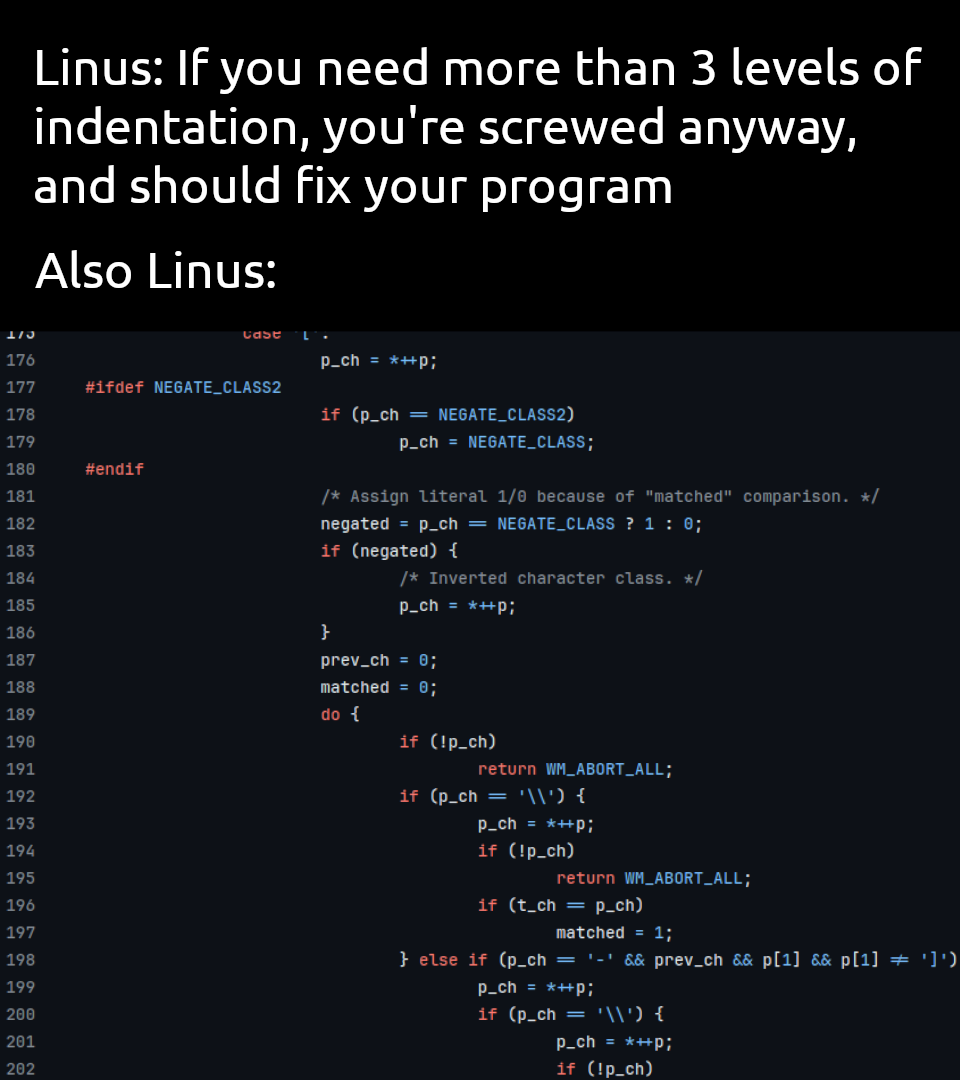
line 152 is the only thing past 3 levels and I’d say that one gets a pass.
You really think someone would do that? Just go on the internet and tell lies?
Plus it shows three levels of indentation. Well… there is the extra one created by the compiler directives, but do they really count?
rules aren’t there to be enforced, they’re there so that when you break them you take a second to think about why.
My personal code readability axe to grind is nested complex ternary operators.
Every now and then I’ll see something like this
return (checkFormatType(currentObject.type==TYPES.static||currentObject type==TYPES.dynamic?TYPES.mutable:TYPES.immutable)?create format("MUTABLE"):getFormat(currentObject));And I have a fucking conniption because just move that shit into a variable before the return. I get it when sometimes you just need to resolve something inline, but a huge amount of the time that ternary can be extracted to a variable before the ternary, or just rewrite the function to take multiple types and resolve it in the function.
In a one-liner competition, sure.
In my codebase? I’d pull a “let’s linger after standup about your PR” and have the coder sweat through a 10 minute soapbox about nothing before laying down the law.
no but bro, the code complexity tool says that this scope has 14 complexity instead of 13, we gotta cram it in a single ternary for code legibility
Only the sith deal in absolutes
You must be a sith…
They might be a sith.
Ah shit…
Absolutely.
While I totally agree with that philosophy, it heavily depends on the language.
For Rust, my philosophy is more like this:
- Impl + fn body don’t count, as well as async blocks if they span the whole function
- do not nest more than one if statement. You probably better using guard clauses or matches
- do not put loops into an if statement.
- do not nest loops unless clearly shown to be (X, Y) indexing
- method chaining is free
- do not nest closures, unless the nested closure doesn’t have a {} block
- do not use mod unless it’s test for the current module. No I don’t want to Star Wars scroll your 1000 line file. Split it.
Why have an async block spanning the whole function when you can mark the function as async? That’s 1 less level of indentation. Also, this quite is unusable for rust. A single match statement inside a function inside an impl is already 4 levels of indentation.
Those async blocks exist when doing async in traits.
And I never said I respected the 4 level of indentations. That’s exactly the point of those rules. Keep it lowly indented but still readable
A single match statement inside a function inside an impl is already 4 levels of indentation.
How about this?
The preferred way to ease multiple indentation levels in a
switchstatement is to align theswitchand its subordinatecaselabels in the same column instead of double-indenting the case labels. E.g.:switch (suffix) { case 'G': case 'g': mem <<= 30; break; case 'M': case 'm': mem <<= 20; break; case 'K': case 'k': mem <<= 10; /* fall through */ default: break; }I had some luck applying this to
matchstatements. My example:let x = 5; match x { 5 => foo(), 3 => bar(), 1 => match baz(x) { Ok(_) => foo2(), Err(e) => match maybe(e) { Ok(_) => bar2(), _ => panic!(), } } _ => panic!(), }Is this acceptable, at least compared to the original
switchstatement idea?i personally find this a lot less readable than the
switchexample. thecasekeywords at the start of the line quickly signify its meaning, unlike with=>after the pattern. though i dont speak for everybody.How about this one? it more closely mirrors the switch example:
match suffix { 'G' | 'g' => mem -= 30, 'M' | 'm' => mem -= 20, 'K' | 'k' => mem -= 10, _ => {}, }How about this other one? it goes as far as cloning the switch example’s indentation:
match suffix { 'G' | 'g' => { mem -= 30; } 'M' | 'm' => { mem -= 20; } 'K' | 'k' => { mem -= 10; } _ => {}, }
It’s a lot less readable imo. As well than a
cargo fmtlater and it’s gone (unless there’s a nightly setting for it)Formatters are off-topic for this, styles come first, formatters are developed later.
My other reply:
How about this one? it more closely mirrors the switch example:
match suffix { 'G' | 'g' => mem -= 30, 'M' | 'm' => mem -= 20, 'K' | 'k' => mem -= 10, _ => {}, }How about this other one? it goes as far as cloning the switch example’s indentation:
match suffix { 'G' | 'g' => { mem -= 30; } 'M' | 'm' => { mem -= 20; } 'K' | 'k' => { mem -= 10; } _ => {}, }I mean, I use formatters everywhere I can exactly so I don’t have to think about code style. I’ll take a full code base that’s consistent in a style I dislike, over having another subjective debate about which style is prettier or easier to read, any day. So whatever
cargo fmtspits out is exactly what I’ll prefer, regardless of what it looks like, if only for mere consistency.
Well, of course you can have few indent levels by just not indenting, I don’t think the readability loss is worth it though. If I had give up some indentation, I’d probably not indent the impl {} blocks.
I just got some idea yesterday regarding
implblocks, ready to be my respondent?I had a big
implblock with 4 levels of indentation, so I cut the block, and replacedimpl InputList { //snip }with
mod impl_inputlist;and moved theimplblock to a new file, and did not indent anything inside that block.The advantage this has over just not indenting the
implblock in place, is that people will have difficulty distinguishing between what’s in the block and what’s outside, and that’s why theimplwas moved to its own exclusive file, impl_inputlist.rsMaybe I am overstressing indentation. Ss there something wrong with my setup that prevents me from accepting 4-space indentation?
I use:
Editor: Neovide
Font: “FiraCode Nerd Font Mono:h16” (16px fonts are addicintg)
Monitor: 1366x768, 18.5 inch, 10+ years old, frankenstein-ly repaired Samsung monitor.
Distance: I sit at about 40-60 Cm from my monitor.
That leaves me with a 32x99 view of code excluding line numbers and such.
I didn’t know why, but *++p bugs me
welcome to C
Perhaps *(p += 1) will be to your liking?
p = 1 x = ++p // x = 2 // p = 2p = 1 x = p++ // x = 1 // p = 2++pwill increase the value and return the new valuep++will increase the value and return the old valueI think
p = p + 1is the same asp++and not as++p. No?(p += 1) resolves to the value of p after the incrementation, as does ( p = p + 1).
Yes.
p++==p+= 1==p = p + 1are all the same if you use it in an assignment.++pis different if you use it in an assignment. If it’s in its own line it won’t make much difference.That’s the point I was trying to make.
No.
++p returns incremented p.
p += 1 returns incremented p.
p = p + 1 returns incremented p.
p++ returns p before it is incremented.
Much better… but can we make it
*((void*)(p = p + 1))?How about some JavaScript
p+=[]**[]?
That
*++operator from C is indeed confusing.Reminds me of the goes-to operator:
-->that you can use as:while(i --> 0) {That’s not a real operator. You’ve put a space in “i–” and removed the space in “-- >”. The statement is “while i-- is greater than zero”. Inventing an unnecessary “goes to” operator just confuses beginners and adds something else to think about while debugging.
And yes I have seen beginners try to use <-- and --<. Just stop it.
The sheer number of people that do not expect a joke on this community… (Really, if you are trying to learn how to program pay attention to the one without the
Humoron the name, not here.)Well, I guess nobody expects.
One nit: whatever IDE is displaying single-character surrogates for
==and!=needs to stop. In a world where one could literally type those Unicode symbols in, and break a build, I think everyone is better off seeing the actual syntax.I think it’s a lineature. FiraCide does that for example, and I like it very much. My compiler and lsp will tell me if there is a bad char there. Besides, the linea tires take the same space as two regular characters, so you can tell the difference.
It’s not the 90s anymore. My editor can look nice.
Ligature, not lineature.
In a world where your IDE and maybe also compiler should warn you about using unicode literals in source code, that’s not much of a concern.
VSCode (and I’m sure other modern IDEs, but haven’t tested) will call out if you’re using a Unicode char that could be confused with a source code symbol (e.g. i and ℹ️, which renders in some fonts as a styled lowercase i without color). I’m sure it does the same on the long equals sign.
Any compiler will complain (usually these days with a decent error message) if someone somehow accidentally inserts an invalid Unicode character instead of typing
==.
Broad generalizations aren’t for the people who make them, they’re for the suckers who consistently fall for them
The number one thing that gets in my way of refactoring to function is figuring out what to name the functions takes too long.
Why is multiple levels of indentation bad?
IDK, but if the reason is “to break stuff into multiple functions”, then I’m not necessarily writing yet another single-use function just to avoid writing a comment, especially in time critical applications. Did that with a text parser that could get text formatting from a specifically written XML file, but mainly due to it being way less time critical, and had a lot of reused code via templates.
Like with everything, context matters. Sometimes it can indicate poorly structured control flow, other times inefficient loop nesting. But many times it is just somebody’s preference for guard clauses. As long as the intent is clear, there are no efficiency problems, and it is possible to reach the fewest branches necessary, I see no issues.
It’s important to remember that Linus is primarily writing about C code formatting. C doesn’t have things that tend to create more deeply nested structures, such as a formal class syntax, or nested functions.
Going too deep is still bad–as zea notes, it’s an indication of control structures run amok–but the exact number is dependent on the language and the context.
Indentation implies there’s some control structure causing it. Too many control structures nested gets hard to mentally keep track of. 3 is arbitrary, but in general more indentation => harder to understand, which is bad.





{kind=link}